本篇文章要介紹在 dplyr 的一些常用函數,除了上次介紹的 filter 和 arrange ,今天會介紹 select 和 mutate。
library(tidyverse)
library(nycflights13)
今天我們使用的一樣是 nycflights13 裡頭的 flights 這筆資料。
glimpse(flights)

可以看到它是336776x19的資料框,有就是我們有336776筆資料,且有19種變數。
因為可能會有我們暫時不需要的變數,所以我們可以使用 select 去縮小我們的資料框。如下:
select(flights,year,month,day)

如此以來我們就會變成336776x3的資料框,語法和上次的函數類似,前面是填入你的資料,而後面就是你想要留下的變數,也可以有一些特別的操作。
select(flights,year:day)

上述程式碼代表的是選擇year到day之間的所有變數,因為之間只有month,所以一樣是336776x3的資料框。其實也可以用扣的!
select(flights,-(year:day))
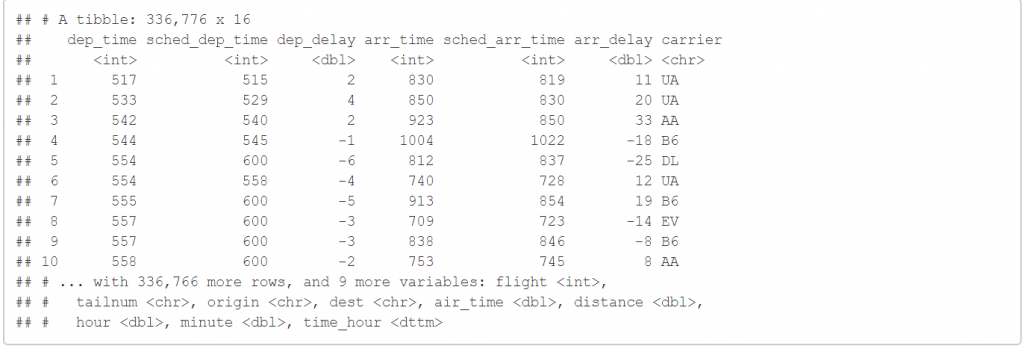
上述程式碼會把除了year,month,day以外的變數都留下來。
而select裡面還有一些其他的語法。
select(flights,starts_with("dep"))

starts_with ("dep") 會把開頭是"dep"的變數都留下來。
select(flights,ends_with("time"))
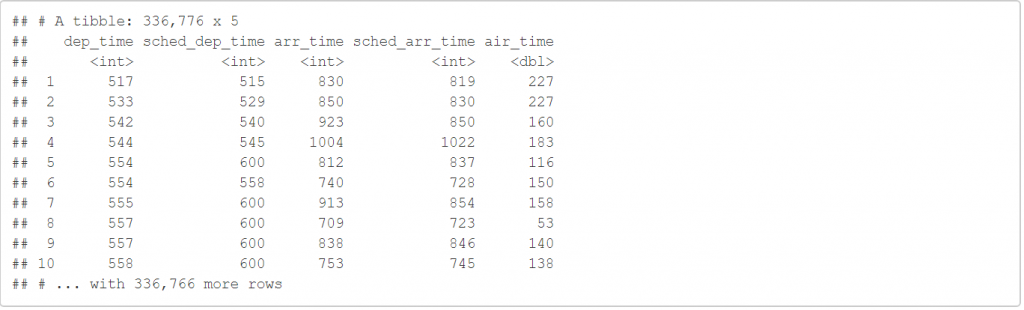
ends_with("time") 會把結尾是"time"的變數都留下來。
select(flights,contains("rr"))
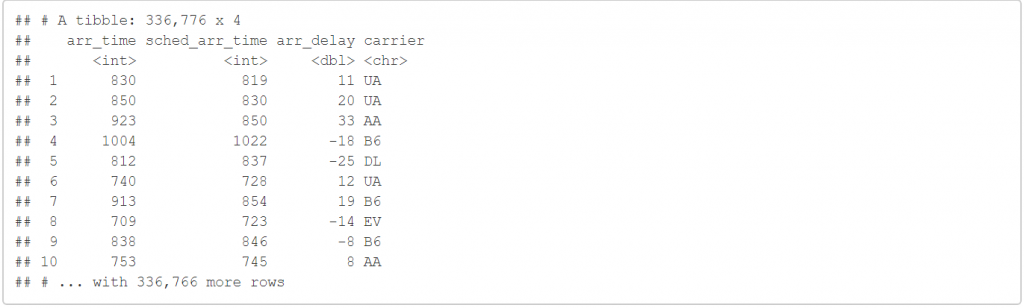
contains("rr") 會把變數中含有"rr"字串的變數都留下來。
我們也可以利用 rename 進行變數改名。
n_flights<-rename(flights,ABC=tailnum)
glimpse(n_flights)

也可以搭配 everything() 把一些變數移至前面。
select(flights,time_hour,air_time,everything())
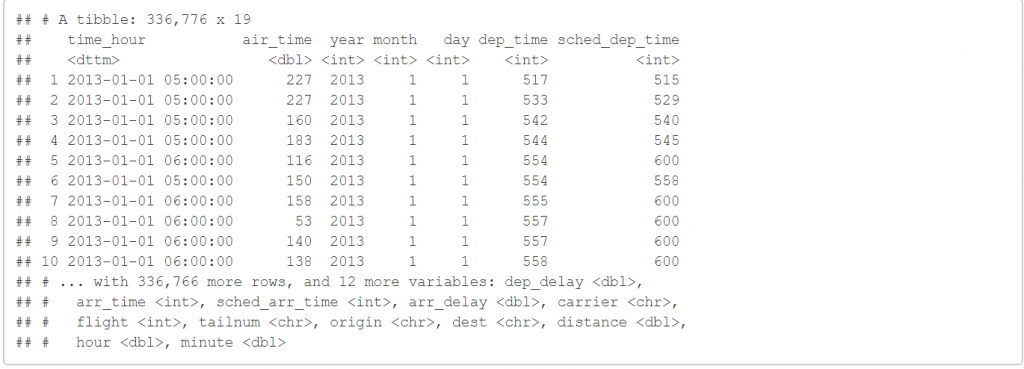
這段程式碼的意思是將 time_hour 和 air_time 放到第一和第二行,其他則按照原本的順序。
如果你想要新增變數,那我們可以使用 mutate 。
mutate(flights,gain=arr_delay-dep_delay)
即可增加新的變數,所以如果你想在資料間做運算是很輕易可以達成的,而 transmute 可以只留下新增的變數。
transmute(flights,gain=arr_delay-dep_delay)

當然你也可以搭配以些四則運算在內部,或是一些內件計算函數,如:sum(),log(),log2()等等。
像是
transmute(flights,a=air_time/60)

就可以對整行做統一的除法,或是
transmute(flights,b=(sched_arr_time)/sum(sched_arr_time))

就可以看出對於整體來說,各資料所佔的比例。也可以取log去做資料調整。
transmute(flights,c=log(sched_arr_time))

當然它的內建函數還很多,我們最後介紹一些常見的排序函數。
(y<-c(1,9,2,NA,3,4))
min_rank(y)


如果這個函數無法滿足你,也可以試試 row_number() dense_rank percent_rank cume_dist ntile 。
這些都是一些常用來做排序的常見函數,這次的介紹到這裡,謝謝大家。下一次我會介紹分組摘要 summarize ,它一樣是dplyr的內部函數,在資料分析中也佔著重要的角色。
 df568923
df568923
